An Introduction to Maximum Likelihood Estimation
Maximum likelihood estimation is a fundamental technique in statistics. Here I give an introduction to the topic, and lay the groundwork for future posts covering its uses and extensions.
In statistics, maximum likelihood estimation (MLE) is a fundamental technique used to estimate the parameters of a probability distribution based on observed data. The mathematical formulation of MLE can be intimidating if you haven’t seen it before, but the idea motivating it is extremely simple and has deep connections to abductive reasoning, also known as inference to the best explanation. Here, I go over the basics of MLE for future posts covering its uses and extensions. To begin, let’s informally discuss a concrete example and then we’ll try to generalize what we learn from it and get more rigorous.
Note: in this post I use MLE to refer both to the technique of maximum likelihood estimation, but also to the estimate itself
Flipping Biased Coins
Imagine you are given a biased coin (a coin for which the odds of flipping heads or tails is not ) and are tasked with approximating the probability with which it lands heads. You have nothing at your disposal, no way to directly measure the weightedness of the coin. All you can do is flip it and see the outcome. How do you go about doing this? Your intuition probably tells you to observe a bunch of coin flips and simply count the frequency of heads. Our gut tells us that for a sufficiently high number of flips this number should approach the true probability. But is there a way to reason our way there without relying purely on intuition? Let’s try.
Firstly, since we know there are only two possible outcomes we can say that if then it must be the case that . Additionally, we know that we have to observe a large number of flips before we can say much of anything about the probabilities, and we also know that these flips are all independent of one another. Let’s call the number of flips we observe . Finally, if you’ve been exposed to basic probability theory you might remember that the probability of two independent events co-occuring is the product of their individual probabilities. To convince yourself of this, consider the case of flipping two fair coins. The probability of observing any one pair is because we have distinct outcomes, for each coin A1.
With this information we can write the probability of observing a particular set of coin flips which we denote as given a particular probability of flipping heads :
where is the number of times we flip heads and is the number of times we flip tails.
Now, ask yourself the following question: given some observed set of flips , what value for maximizes ; what value of makes our observed dataset most probable? Said another way, given a set of flip outcomes, what value for could we choose that would maximize the chances of observing those outcomes? That number is the maximum likelihood estimate.
At first encounter the MLE estimate can often feel slippery or circular. We are using our data to approximate a model that best explains…our data. However, MLE is really the operationalization of a deep intuition: given an outcome, what conditions would have most likely led to that outcome? The mathematical formulation may not be as intuitive, but the underlying idea is beautifully straightforward.
"At a superficial level, the idea of maximum likelihood must be prehistoric: early hunters and gatherers may not have used the words 'method of maximum likelihood' to describe their choice of where and how to hunt and gather, but it is hard to believe they would have been surprised if their method had been described in those terms."(Stigler, 2007)
If we have some data, and we are willing to assume that it comes from a particular distribution (a normal distribution, for example), along with some other things, then MLE finds what parameters to give that distribution to make it most consistent with our data. In this example we arrived at our distribution through reasoning about the flipping process, and now we are trying to find the value for its parameter which will best explain our data.
Okay, lets see MLE in action. We are tasked with solving the following optimization problem
The solution to said problem will be our estimate which is the approximate probability of our biased coin flipping heads. To start we can notice that whatever argument maximizes our function will also maximize its logarithm. This is because the logarithm is a monotonically increasing function. Reframing the problem this way will allow us to get rid of those annoying exponents and turn multiplication into addition A2.
So far all we have done is some algebraic manipulation of . Now to solve the optimization problem, we can take the derivative of our function and solve for its maximum by setting that equal to zero.
Now we set our equation equal to , replace with , and solve. For succinctness I will write as
And so at the end of all of that we find that the maximum likelihood estimate for the probability of flipping heads given a dataset is simply the frequency of head occurences in our data. Our intuitions have been confirmed! That was a lot of math for such a simple answer, but granted this was a pretty simple problem. Can the MLE generalize to a larger problem space where it’s harder for our intuition to guide us? The answer is yes, but before we get there, lets simulate some coin flips and see how our estimate does as the size of our dataset increases.
import matplotlib.pyplot as plt
import numpy as np
# Parameters
true_theta = 0.65 # True theta
n_flips = 1000 # Number of coin flips
trials = 50 # 50 trials of 1000 flips each
trial_outcomes = []
for trial in range(trials):
# Simulate coin flips
outcomes = np.random.binomial(n=1, p=true_theta, size=n_flips) # 1 is heads, 0 is tails
mle = np.cumsum(outcomes) / np.arange(1, n_flips + 1)
trial_outcomes.append(mle)
# Plotting
for i, outcome in enumerate(trial_outcomes):
if i == 0:
plt.plot(outcome, label=r'$\frac{k}{n}$', lw=0.6)
else:
plt.plot(outcome, lw=0.6)
plt.axhline(y=true_theta, color='black', linestyle='--', label='True Probability of Heads')
plt.title('50 Estimates of P(H)')
plt.xlabel('Number of Coin Flips')
plt.ylabel('Cumulative Probability of Heads')
plt.legend()
plt.tight_layout()
plt.show()
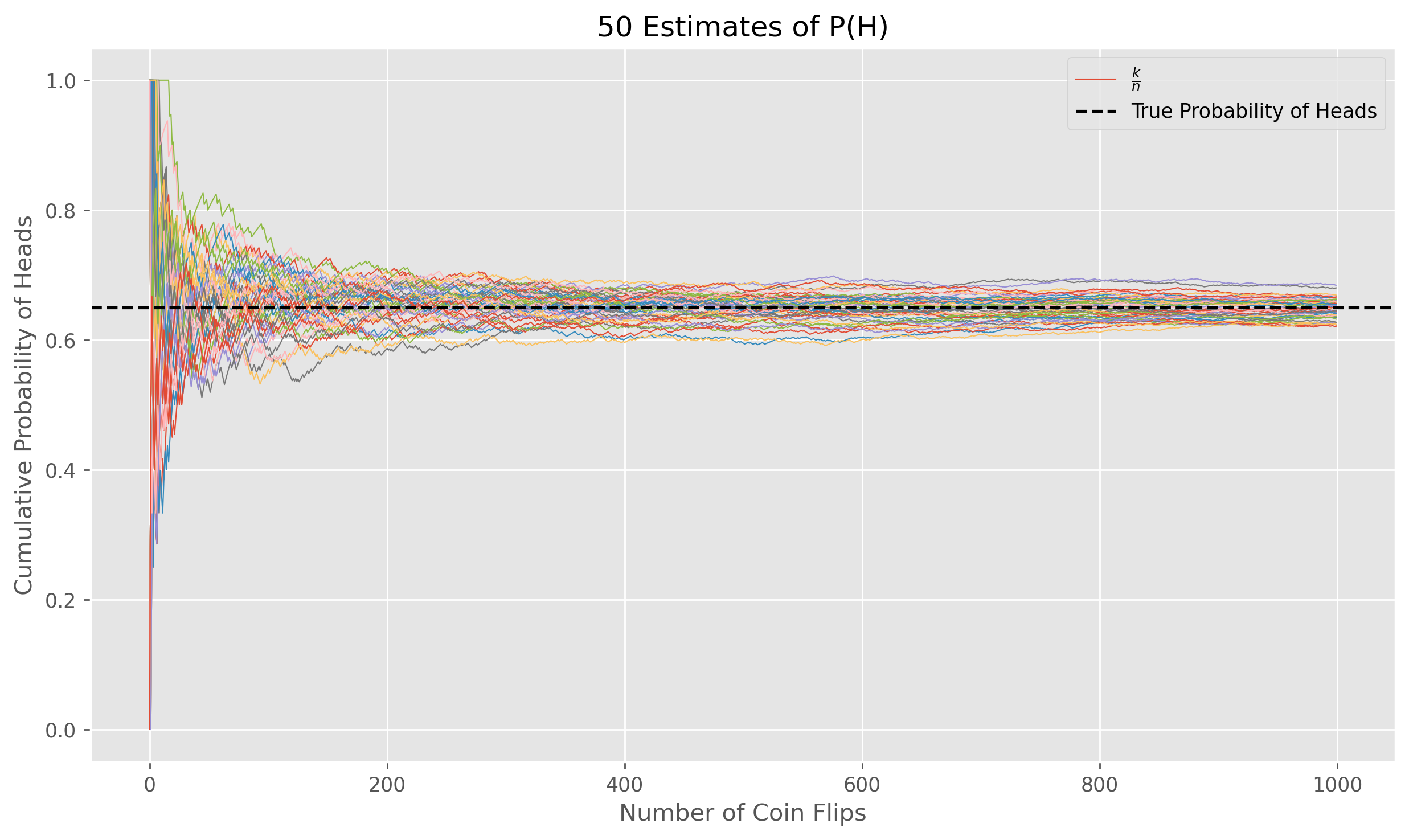
In the image above, I plot the evolution of estimates of as more coin flip landings are observed and used to update the MLE. Qualitatively we can tell our intuition that “more data is better” was also correct. As gets larger we see our estimates getting closer to the true value, albeit with most of the progress happening within the first observations. In fact, although we won’t prove it here, under some basic assumptions it can be shown that in the limit, as our number of data points approaches infinity, the MLE estimate actually converges to the true value of .
Generalizing the MLE
One of the most compelling attributes of maximum likelihood estimation is its broad applicability. MLE is not limited to specific distributions or data types; it can be applied to any situation where a likelihood function can be constructed. However, in its simplest formulation (the one discussed in this post) there are some strong assumptions we have to make about our data for the technique to work well. In the remainder of this post I will go over MLE in its general formulation and highlight what those assumptions are.
We begin by observing a set of data points
which are assumed to be independent and identical samples from a probability distribution , where represents the domain of the distribution and represents its parameters. We don’t know the value(s) of (that’s the point of MLE) but we know the class of distributions (normal, Poisson, etc.) to which belongs. Ultimately what we want from MLE is a data informed approximation of which we refer to as . Using this estimate we will be able to paramaterize a distribution which reflects our observations and which allows us to make statistical propositions about our dataset.
The first step in MLE is to construct a likelihood function
The above equation says that our likelihood function is the cumulative product (A3) of our probability distribution evaluated at each of our data points for a given parameterization . The fact that the likelihood is a function over the parameters and not the data is important to note and implicit in this equation is all of the assumptions needed for MLE:
(1) Our data is comprised of independent, uncorrelated samples (hence the cumulative product)
(2) Each data point was sampled identically ( is unchanging across data points)
(3) We know the form of , though obviously not the exact values of
But what does the likelihood function actually tell us? The likelihood function serves as a bridge between our data and our possible choices for parameters. It is a function that quantifies the ability of a particular estimate of to explain our data. If we were to choose a value for and plug it in to we would get a number quantifying the plausibility of that given the observed data. Note that previously we were using the notation , but this is really the same idea. For a given value of what is the probability of our data?
To make this point more clear, let’s go back to the coin example. If we were to flip our coin times and observe that it landed on heads out of those , what would be the shape of ? The function now looks like
What does this look like plotted?
def likelihood_function(n_heads: int, n_tails: int, theta: float) -> float:
return (theta ** n_heads) * ((1 - theta) ** n_tails)
theta_values = np.linspace(0, 1, 1000)
heads, tails = 8, 2
plt.plot((likelihood_function(heads, tails, theta_values)))
plt.xticks(np.arange(0, 1001, 100), [f'{0.1 * i:0.2f}' for i in range(11)])
plt.xlabel(r'$\theta$')
plt.ylabel(r'$\mathcal{L}(\theta)$')
plt.legend()
plt.show()
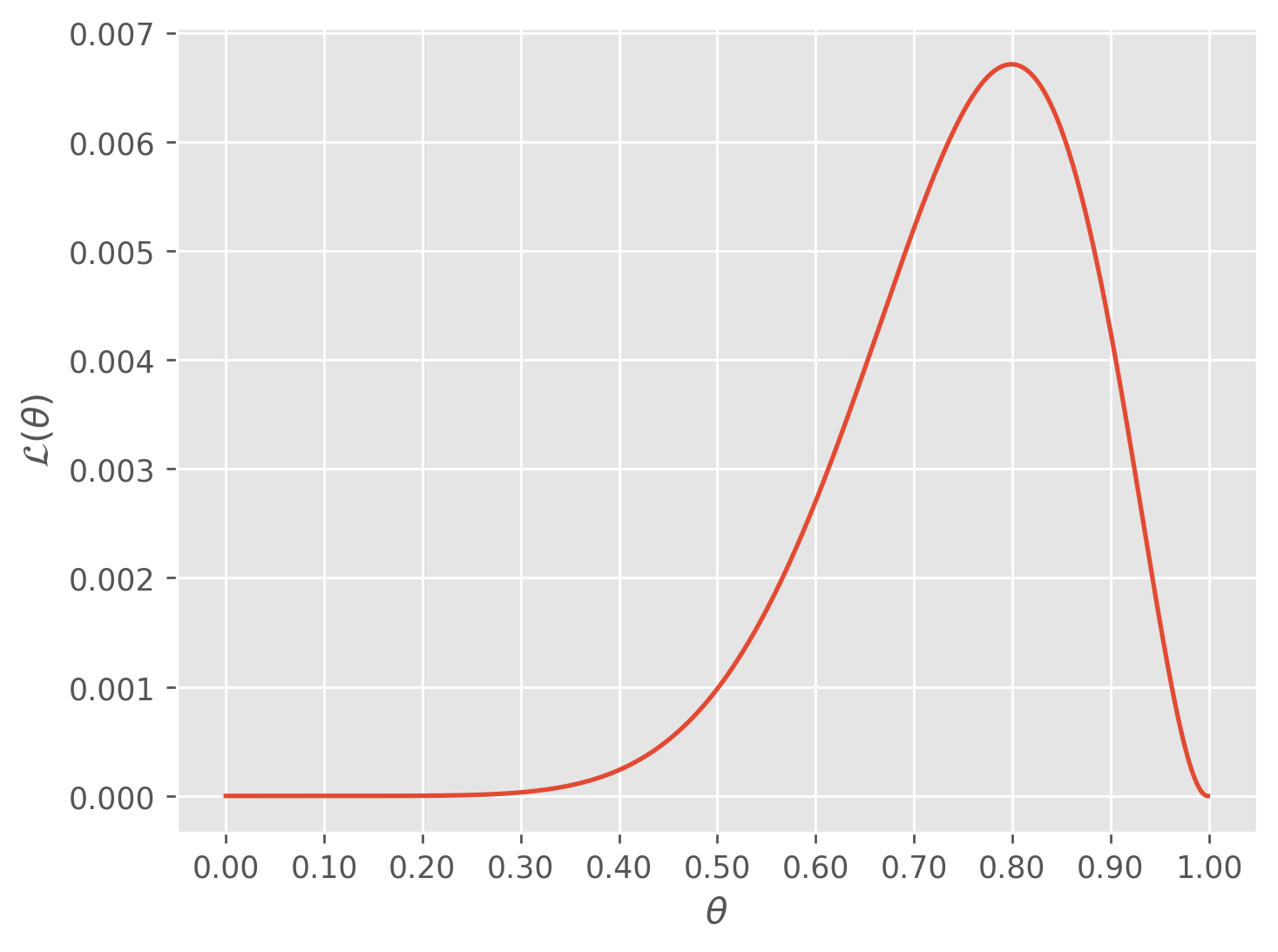
As you can see, our function is clearly maximized at exactly as expected from our work in the previous section. This is the big point of MLE. If we were to choose any value but for , which is the probability of our data under different choices of , would be smaller. Thus given the data the probability of observing our data is maximized when we choose
What would look like for a different set of observations? If we were to have some other frequency of heads, the curve above would swing between and but would always have a maximum value at
theta_values = np.linspace(0, 1, 1000)
heads = np.arange(11)
for n_heads in heads:
n_tails = 10 - n_heads
likelihood = likelihood_function(n_heads, n_tails, theta_values)
plt.plot(likelihood / np.linalg.norm(likelihood), label=fr'$k = {n_heads}$')
plt.xticks(np.arange(0, 1001, 100), [f'{0.1 * i:0.2f}' for i in range(11)])
plt.xlabel(r'$\theta$')
plt.ylabel(r'$\frac{L(\theta)}{\Vert L(\theta)\Vert_2}$')
plt.legend(ncol=2)
plt.show()
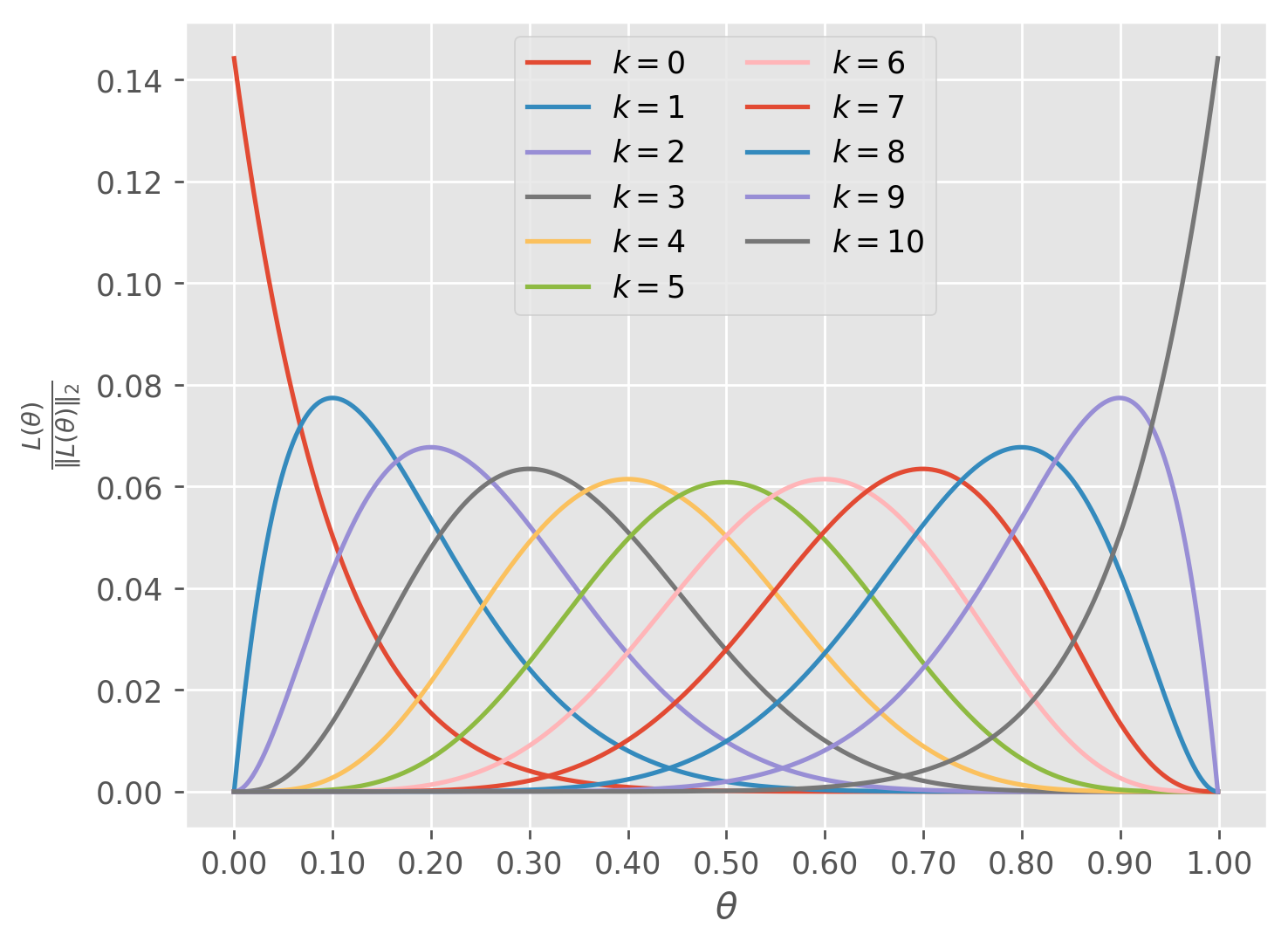
So now if we understand that the likelihood function allows us to put a value for in and get a measure of its ability to explain our data out, it follows that if we want to find an approximation for the true we should choose the which maximizes the likelihood function.
Let’s now continue with our generalized version of MLE.
The raw likelihood function is
.
In general, products are more difficult to work with than sums, both analytically and numerically, and so in practice we always work with the log-likelihood function .
As was noted before, transforming the likelihood function like this does not change the which maximizes the function. Now, all that’s left to do is find the over . Typically this involves taking the derivative of and finding the global maximum by solving for the value of that makes that equal .
Depending on the specifics of the particular likelihood function this may be difficult to do analytically.
A Final Example
As a final example let’s find the maximum likelihood estimate for the Poisson distribution which has parameter . The Poisson distribution expresses the probability of a given number of events happening in a fixed interval of time or space, and is given by
where is the number of events and is the mean rate of occurences in the interval.
Thus, the maximum likelihood estimator for the Poisson distribution is simply the sample mean.
Appendix
A1
If this seems unintuitive to you, imagine you have a pair of unweighted -sided die and want to know the probability of rolling a with both of them. If you were to roll a first, you haven’t effected the outcome of the second roll and so there are still possible outcomes. The key is to realize that this is actually true no matter what number we roll first and so for each outcome of the first roll we have possible outcomes for the second. Thus our total number of possibilities is and so the probability of any one outcome is . In fact, if we had die then we would have possibilities each with probability . Or if we added a coin flip we would have possibilities each with probability because for each of the outcomes from the die rolling we could flip either heads or tails. All of this is a function of the events being independent from one another, and would not work if the outcomes of one process altered the outcomes of another.
A2
The logarithm of a product is the sum of the logarithms of the products factors
Notice that this necessitates
A3
If you aren’t familiar with this notation, capital pi is used to denote the cumulative product of a sequence.
This is exactly what we did for the flipped coin example, where we wrote the likelihood as the cumulative product of the probability of each flip. In that example there were only two possible probabilities and so there was no need for this notation, we could just use exponents.
- Stigler, S. M. (2007). The Epic Story of Maximum Likelihood. Statistical Science, 22(4). https://doi.org/10.1214/07-sts249